DeepSeekOCR 的成功让许多人误以为“视觉编码”是压缩的关键。然而,研究团队经过深入分析发现,高压缩率的核心其实源自 Latent Tokens(潜在 Token)本身——这是一种比离散文本 Token 更高效、密度更高的信息载体。
基于这一洞察,作者所在的研究团队提出了一种直击本质的全新路径:Context Cascade Compression (C3,上下文级联压缩)。
将两种路径进行对比:
DeepSeek OCR 路径: 文本 → 图像 → 视觉 Token → 语言模型(引入了布局、噪点、视觉编码器等无关干扰)
C3 路径: 文本 → 文本 Latent Tokens → 语言模型(纯粹、无损、直接)
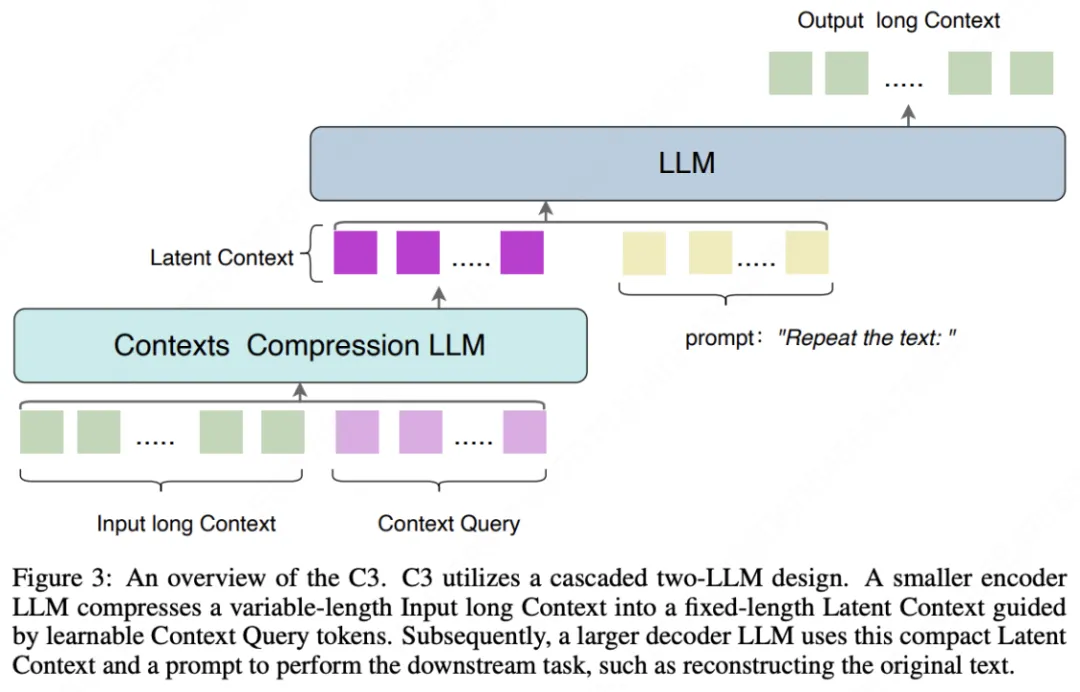
具体来说,一个小型 LLM 作为第一级,通过将长上下文压缩成一组潜在 token(例如,长度为 32 或 64),实现高比例的文本 token 到潜在 token 的压缩。一个大型 LLM 作为第二级,然后对这个压缩的上下文执行解码任务。
这一设计也验证了近期热门论文《LANGUAGE MODELS ARE INJECTIVE AND HENCE INVERTIBLE》中关于「LLM 本质是无损压缩」的论断。
实验表明,在 20 倍压缩比(文本 token 数量是潜在 token 数量的 20 倍)下,C3 实现了 98% 的解码准确率,而 DeepSeek OCR 大约为60%。当我们进一步将压缩比增加到 40 倍时,准确率仍保持在约 93%。这表明在上下文压缩领域,C3 压缩比光学字符压缩展示了更优越的性能和可行性。
目前模型与代码现已开源:
- 原文:https://arxiv.org/pdf/2511.15244
- 代码:https://github.com/liufanfanlff/C3-Context-Cascade-Compression
- 模型:https://huggingface.co/liufanfanlff/C3-Context-Cascade-Compression
架构
在介绍 C3 之前,先带大家来了解一下 DeepSeek-OCR 的工作原理。DeepSeek-OCR 采用了一种创新的"视觉压缩"思路,这种方法的优势在于利用了视觉编码器强大的特征提取能力,但也面临着图像布局复杂性、低分辨率下的模糊等固有限制。C3 提出了一个更直接的压缩思路:跳过视觉中介,没有中间商赚差价,直接在文本域进行压缩。其核心架构包括:
1.双 LLM 级联设计
- 小型 LLM(算力消耗低)作为压缩编码器,压缩上下文信息。
- 大型 LLM(推理生成能力强)作为解码器执行下游任务。
2.压缩机制
- 引入可学习的"上下文查询"(Context Query)嵌入
- 将长文本压缩为固定长度的潜在token(如32或64个)。
- 完全保留预训练 LLM 的语言压缩能力
性能表现
在 Fox 基准测试中,C3 展现出显著优势:
- 在约 20 倍压缩时,C3 保持 98.4% 精度,而D eepSeek-OCR 降至59.1%
- 即使在极限的 40 倍压缩率下(32 个潜在 token),C3 仍能维持 93% 以上的重建精度
独特的"遗忘模式":更接近人类记忆

研究还发现了 C3 的一个有趣特性:当压缩率过高导致信息损失时,错误往往集中在文本末尾,呈现序列性信息衰减。这与光学压缩方法的"全局模糊"不同,反而更类似人类记忆的渐进式遗忘过程。
这种特性使得 C3 在实际应用中更具可预测性——重要信息可以优先放置在文本前部,确保关键内容的完整保留。
测试

- 无论是在长英文文本还是中文古文上均做到了近乎完美的压缩还原
- 甚至对于 LLM 一直难以处理的乱序文本也能精准还原
应用前景
- 1. 超长上下文处理:C3 可作为现有 LLM 的"前端压缩器",将百万级 token 的输入(如整本书籍、大型代码库)压缩到可处理范围,降低计算成本。
- 2. 多模态:级连轻量级 VLM 和 LLM,轻量级 VLM 作为视觉 encoder 进行信息压缩,处理视觉信息丰富的长文档等。
- 3. 下一代模型的基础组件 :C3 的编码-解码架构可直接应用于扩散语言模型和潜在自回归模型,将可变长度文本转换为固定长度潜在表示。
- 这是一个在有限的人力、算力与数据背景下诞生的“小而美”项目。
- 目前 C3 的代码与权重开源,希望开源社区的研究者们能接过这一棒,激发出C3 的巨大潜能。
本文由公众号“AI科技大本营”授权转载| https://mp.weixin.qq.com/s/0TfoM48EPlLfceZ6xCyL5Q |(编辑:ZN)

⬆ 扫码加入AI产品交流社群,你有机会得到:
- 最值得关注的AI产品;
- 最新鲜的 AI 产品资讯;最实用的AI产品使用经验;
- 还有不定期赠送热门新品的邀请码、会员码。